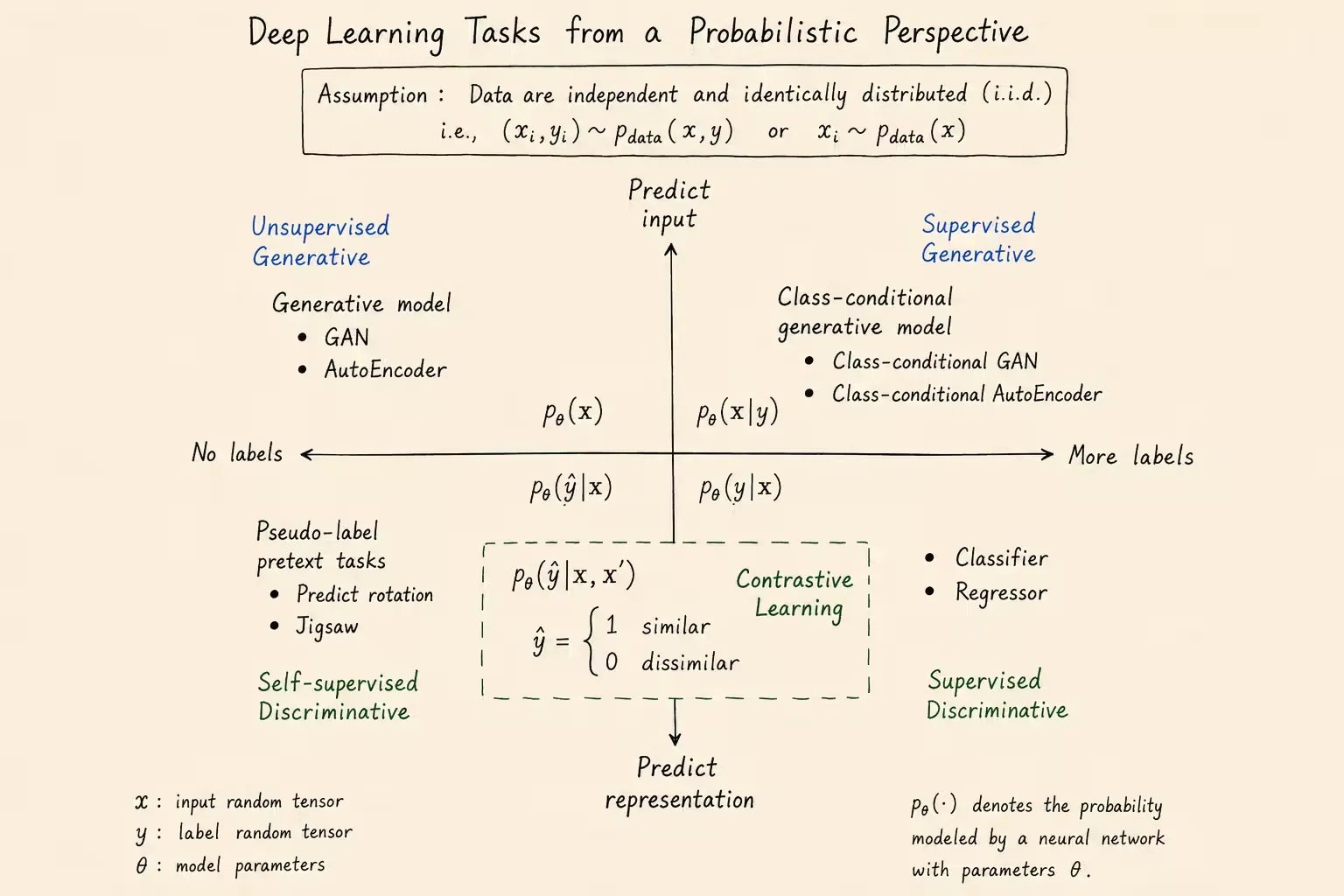
从概率视角看,深度学习模型的训练就是选择一组参数θ,让模型分布尽可能贴近数据分布
设数据集为有标签形式D={(xi,yi)}i=1N,或无标签形式D={xi}i=1N。常见任务可以按模型要学习的概率分布划分:
- 有监督判别:根据输入预测真实标签,即pθ(y∣x)
- 自监督判别:根据输入预测伪标签,即pθ(y^∣x)
- 有监督生成:根据标签生成对应样本,即pθ(x∣y)
- 无监督生成:直接学习样本空间分布,即pθ(x)
其中x表示输入随机张量,y表示标签随机变量,θ表示模型中的可学习参数
本文默认输入样本满足独立同分布(independent and identically distributed, i.i.d.)假设。这个假设让数据集似然可以拆成单样本似然的乘积,也让后续最大似然推导成立
有监督判别
有监督判别任务拥有数据集D={(xi,yi)}i=1N。训练目标是让模型在给定输入xi时,尽可能高概率地预测真实标签yi
设模型f(x,θ)将输入映射到潜在表示zi或zi,其中zi=f(xi,θ)∈RK。最大化数据集条件似然可写为:
θML=argθmaxpθ(D)=argθmaxpθ(y1,y2,…,yN∣x1,x2,…,xN)=argθmaxi=1∏Npθ(yi∣xi)(i.i.d.)=argθmaxi=1∏Np(yi∣zi)=argθmaxi=1∑Nlogp(yi∣zi)=argθmin−i=1∑Nlogp(yi∣zi)
不同任务只是在标签随机变量y上选择了不同的条件分布。例如,回归常用正态分布,二分类常用 Bernoulli 分布,多分类常用 softmax 分类分布。
其中sigmoid把标量输出压到[0,1],softmax把向量z=[z1,z2,…,zK]变成分类分布:
p(y∣z)=softmaxy(z)=∑y′=1Kexp[zy′]exp[zy]
更多分布和对应损失见常用概率分布
| 标签数据特性 | 标签域 | 概率分布 | 用途 |
|---|
| 单变量,连续,无界 | y∈R | 单变量正态分布 | 回归 |
| 单变量,连续,无界 | y∈R | Laplace或t 分布 | 稳健回归 |
| 单变量,连续,无界 | y∈R | 混合高斯分布 | 多模态回归 |
| 单变量,连续,有下界 | y∈R+ | 指数或gamma 分布 | 预测大小 |
| 单变量,连续,有界 | y∈[0,1] | beta 分布 | 预测占比情况 |
| 多变量,连续,无界 | y∈RK | 多变量正态分布 | 多变量回归 |
| 单变量,连续,圆周 | y∈(−π,π] | vonMises分布 | 预测角度 |
| 单变量,离散,二值 | y∈{0,1} | Bernoulli 分布 | 二分类 |
| 单变量,离散,有界 | y∈{1,2,…,K} | 分类分布 | 多分类 |
| 单变量,离散,有下界 | y∈{0,1,2,3,…} | Poisson 分布 | 预测事件发生次数 |
| 多变量,离散,排序 | y∈Perm[1,2,…,K] | Plackett−Luce 分布 | 排列 |
标签域特性及概率分布
无监督生成
无监督生成任务只拥有样本D={xi}i=1N。目标是学习数据分布pθ(x),使模型能够从该分布中生成与真实样本相似的新样本
GAN、VAE 和扩散模型都服务于这个目标,但建模方式不同。GAN 用判别器提供训练信号,VAE 通过潜变量模型最大化 ELBO,扩散模型则把生成过程拆成多步去噪
GAN(GenerativeAdversarialNetworks)
GAN训练一个生成器x^=fg(v,θg):V→X,把潜在空间V中的采样映射到样本空间X。
为了训练生成器,GAN 同时训练判别器z=fd(x,θd):X→R,用于区分真实样本和生成样本。
对判别器而言,可以构造联合数据集:
Dunion={xi,1}i=1N∪{x^i,0}i=1M={x~i,yi}i=1N+M
训练时,生成器希望生成样本被判别为真;判别器希望准确区分真实样本和生成样本。形式化目标如下
对于生成器:
θMLg=argθgmaxp(y=1∣z^)=argθgmin−logp(y=1∣z^)(z^=fd(x^,θd))
对于判别器:
θMLd=argθdmaxp(y∣z~)=argθdmin−logp(y∣z~)(z~=fd(x~,θd))
VAE(VariationalAutoEncoders)
VAE同样训练一个解码器x^=fd(v,θd):V→X,把潜变量v映射到样本空间
不同于 GAN,VAE 明确写出潜变量模型,并希望最大化边缘似然pθd(x)。其形式为:
θMLd=argθdmaxpθd(x)=argθdmax∫pθd(x,v)dv=argθdmax∫pθd(x∣v)p(v)dv=argθdmaxlog∫pθd(x∣v)p(v)dv(intractable)
直接最大化log∫pθd(x∣v)p(v)dv通常不可行,因为积分难以解析求解
因此,VAE 转而最大化一个可优化的下界,即证据下界ELBO(Evidence Lower Bound)。当ELBO增大时,边缘对数似然也会被间接推高
logpθd(x)=log∫pθd(x,v)dv=log∫q(v)q(v)pθd(x,v)dv≥∫q(v)logq(v)pθd(x,v)dv(Jensen′sinequality)
因此,我们可以取下界为
ELBO(θd)=∫q(v)logq(v)pθd(x,v)dv
实际训练中,v的近似后验q(v)通常由编码器生成。因此,下界更规范地写作ELBO(θe,θd)
ELBO(θe,θd)=∫qθe(v)logqθe(v)pθd(x,v)dv=∫qθe(v)logqθe(v)pθd(v∣x)pθd(x)dv=∫qθe(v)logpθd(x)dv+∫qθe(v)logqθe(v)pθd(v∣x)dv(oneperspective)=logpθd(x)−DKL[qθe(v)∣∣pθd(v∣x)]=∫qθe(v)logqθe(v)pθd(x∣v)p(v)dv=∫qθe(v)logpθd(x∣v)dv+∫qθe(v)logqθe(v)p(v)dv(anotherperspective)=∫qθe(v)logpθd(x∣v)dv−DKL[qθe(v)∣∣p(v)]≈logpθd(x∣v∗)−DKL[qθe(v)∣∣p(v)](MonteCarloestimate)
上式中的近似后验和先验分别为:
qθe(v)p(v)≈qθe(v∣x)=N(v∣feμ(x,θe),feΣ(x,θe))=N(v∣0,1)
v∗从qθe(v∣x)中采样得到。最大化ELBO(θe,θd)即可同时训练编码器和解码器,并间接建模pθd(x)
DiffusionModels
DiffusionModels也可以看作潜变量生成模型。它们通过训练解码器x^=fd(v,θ):V→X,把噪声逐步还原为样本
与 VAE 类似,扩散模型也可从最大化pθ(x)出发。但这里的潜变量v通常由原始输入x逐步加噪得到,解码器学习反向去噪过程
为简化推导,令v=zT,则前向加噪和反向采样过程为:
forwardprocess:x→z1→z2→⋯→zT−1→zT(v)
reverseprocess:(v)zT→zT−1→zT−2→⋯→z1→x
基于这个框架,可以通过最大化pθ(x)求解θ
θML=argθmaxpθ(x)=argθmax∫pθ(x,z1…T)dz1…T=argθmaxlog∫pθ(x,z1…T)dz1…T(intractable)
和 VAE 一样,直接优化边缘似然通常不可行。因此,需要为下面的对数边缘似然构造一个便于优化的ELBO(θ):
log∫pθ(x,z1,…,zT−1,v)dz1…dzT−1dv
logpθ(x)=log∫pθ(x,z1…T)dz1…T=log[∫q(z1…T∣x)q(z1…T∣x)pθ(x,z1…T)dz1…T]≥∫q(z1…T∣x)logq(z1…T∣x)pθ(x,z1…T)dz1…T(Jensen′sinequality)
也就是说,我们可以取证据下界:
ELBO(θ)=∫q(z1…T∣x)logq(z1…T∣x)pθ(x,z1…T)dz1…T
在 VAE 中,编码器通过参数学习近似后验qθe(v∣x)。而在扩散模型中,前向加噪过程通常是固定的、无参数的
因此,训练解码器时,需要让反向过程pθ(zt−1∣zt)尽可能贴近前向过程诱导出的真实后验q(zt−1∣zt,x)
下面对ELBO(θ)中的log项进一步展开
logq(z1…T∣x)pθ(x,z1…T)=log[q(z1∣x)∏t=2Tq(zt∣zt−1)pθ(x∣z1)∏t=2Tpθ(zt−1∣zt)p(zT)]=log[q(z1∣x)pθ(x∣z1)]+log[∏t=2Tq(zt∣zt−1)∏t=2Tpθ(zt−1∣zt)]+log[p(zT)]=log[pθ(x∣z1)]+log[∏t=2Tq(zt−1∣zt,x)∏t=2Tpθ(zt−1∣zt)]+log[q(zT∣x)p(zT)](Bayes′rule)≈log[pθ(x∣z1)]+t=2∑Tlog[q(zt−1∣zt,x)pθ(zt−1∣zt)]
所以ELBO(θ)可以转变为
ELBO(θ)=∫q(z1…T∣x)logq(z1…T∣x)pθ(x,z1…T)dz1…T≈∫q(z1…T∣x)log[pθ(x∣z1)]dz1…T+t=2∑T∫q(z1…T∣x)log[q(zt−1∣zt,x)pθ(zt−1∣zt)]dz1…T=∫q(z1∣x)log[pθ(x∣z1)]dz1+t=2∑T∫q(zt−1,zt∣x)log[q(zt−1∣zt,x)pθ(zt−1∣zt)]dzt−1dzt=∫q(z1∣x)log[pθ(x∣z1)]dz1+t=2∑T∫q(zt∣x)q(zt−1∣zt,x)log[q(zt−1∣zt,x)pθ(zt−1∣zt)]dzt−1dzt(Bayes′rule)=∫q(z1∣x)log[pθ(x∣z1)]dz1−t=2∑T∫q(zt∣x)DKL(q(zt−1∣zt,x)∣∣pθ(zt−1∣zt))dzt
上式中标色的概率分布都可用正态分布建模。
pθ(x∣z1)=N(x∣fd(z1,θ),σ12I)
pθ(zt−1∣zt)=N(zt−1∣fd(zt,θ),σt2I)
前向过程(ForwardProcess)
z1=1−β1x+β1ϵ1
zt=1−βtzt−1+βtϵt∀t∈2,…,T
其中ϵt∼N(0,I)。前向过程的第一项保留上一时刻信号,第二项注入新的高斯噪声,超参数βt控制加噪速度
将方程形式写成概率形式:
q(z1∣x)=N(z1∣1−β1x,β1I)
q(zt∣zt−1)=N(zt∣1−βtzt−1,βtI)
上述过程形成一个 Markov 链。当T足够大时,q(zT∣x)会接近标准正态分布
基于这些分布,可以推导出q(zt−1∣zt,x):
q(zt−1∣zt,x)μq,tσq,t2=N(zt−1∣μq,t,σq,t2I)=1−αt1−αt−11−βtzt+1−αtαt−1βtx=1−αtβt(1−αt−1)
其中αt=∏s=1t1−βs
扩散损失
原始扩散损失
用正态分布建模各项后,原始扩散损失可以写为:
−ELBO(θ)=n=1∑N(−log[N(xn∣fd(zn1,θ),σ12I)]+2σ21t=2∑Tμq,t(znt,xn)−fd(znt,θ)2)
其中:
μq,t(znt,xn)=1−αt1−αt−11−βtznt+1−αtαt−1βtxn
重参数化扩散损失
由前向过程可得:
zt=αt⋅x+1−αtϵ
x=αt1⋅zt−αt1−αt⋅ϵ
将原始扩散损失中的x改写为zt和噪声ϵ的函数:
−ELBO(θ)=n=1∑N(−log[N(xn∣fd(zn1,θ),σ12I)]+t=2∑T2σt21μ~t(znt,ϵnt)−fd(znt,θ)2)=n=1∑N(2σ121xn−fd(zn1,θ)2+t=2∑T(1−αt)(1−βt)2σt2βt2gd(znt,θ)−ϵnt2+Cn)(Reparameterizationofnetwork)=n=1∑Nt=1∑T(1−αt)(1−βt)2σt2βt2gd(znt,θ)−ϵnt2+Cn
其中:
μ~t(znt,ϵnt)=1−βt1znt−1−αt1−βtβtϵnt
其中网络重参数化使用:
fd(znt,θ)=1−βt1znt−1−αt1−βtβtgd(znt,θ)
于是,训练目标可以进一步简化为预测噪声:
L(θ)=n=1∑Nt=1∑Tgd(znt,θ)−ϵnt2=n=1∑Nt=1∑Tgd(αtxn+1−αtϵnt,θ)−ϵnt2
反向过程(Reverse(Sampling)Process)
由反向概率分布:
pθ(zt−1∣zt)=N(zt−1∣fd(zt,θ),σt2I)
可将概率形式转成采样方程:
zt−1=fd(zt,θ)+σtϵt=1−βt1zt−1−αt1−βtβtgd(zt,θ)+σtϵt
再根据q(zt−1∣zt,x)中的方差项,可以估计:
σt2≈1−αtβt(1−αt−1)≈βt
由此即可从zT逐步采样回x。
自监督学习
给定无标签数据集D={xi}i=1N,自监督学习先从数据本身构造伪标签,形成:
Dfake={xi,y^i}i=1NorDfake={xi,y^i}i=1N
模型z=f(x,θ)把原始输入空间X映射到潜在空间Z,并在该空间中拉开不同伪标签的表示
因此,自监督学习可以看作在伪标签数据集上的有监督判别学习。但它的核心目的不是预测伪标签本身,而是学习可迁移的表示zi,再服务于真实标签的下游任务
对比学习
对比学习是自监督学习中的典型方法。它不依赖人工标签,而是通过构造正负样本对,让模型自动学习有区分力的特征表示
核心思想很直接:相似样本经过模型映射后应尽可能靠近,不相似样本应尽可能分开
设模型f(x,x′,θ)学习概率p(y∣x,X′)。其中候选集合和标签空间为:
X′={x1′,…,xM′},y∈{1,…,M}
y表示正样本索引。
由贝叶斯准则,p(y∣x,X′)∝p(X′∣x,y)p(y)
假设正样本来自真实条件分布pdata(x′∣x),负样本来自噪声分布q(x′)。在条件独立假设下:
p(X′∣x,y)=pdata(xy′∣x)j=y∏q(xj′)
归一化后得到:
p(y∣x,X′)=∑k=1Mq(xk′)pdata(xk′∣x)q(xy′)pdata(xy′∣x)
因此,可以直接参数化密度比:
f(x,x′,θ)≈q(x′)pdata(x′∣x)
并得到:
pθ(y∣x,X′)=∑k=1Mf(x,xk′,θ)f(x,xy′,θ)
上述目标的最大似然形式如下:
θML=argθmaxi=1∏Npθ(yi∣xi,X′)(i.i.d.)=argθmaxi=1∑Nlogpθ(yi∣xi,X′)=argθmaxi=1∑Nlog∑k=1Mf(xi,xk′,θ)f(xi,xyi′,θ)=argθmin−N1i=1∑Nlog∑k=1Mf(xi,xk′,θ)f(xi,xyi′,θ)=argθminN1i=1∑Nlog[1+f(xi,xyi′,θ)∑k=yif(xi,xk′,θ)]=argminExlog1+pdata(xyi′∣x)q(xyi′)k=yi∑q(xk′)pdata(xk′∣x)≈argminEx[log[1+(M−1)pdata(xyi′∣x)q(xyi′)k=yi∑q(xk′)q(xk′)pdata(xk′∣x)=argminEx[log[1+pdata(xyi′∣x)q(xyi′)(M−1)]]≥argminEx[log[pdata(xyi′∣x)q(xyi′)M]]=argminEx[log[pdata(xyi′∣x)q(xyi′)M]]=argmin−I(X′,x)+logM
因此,最大化p(y∣x,X′)也可以理解为最大化X′和x之间的互信息
从优化效果看,对比学习让x和对应正样本X′的耦合程度增大,也就是保持正样本对齐,同时拉开负样本
常用概率分布
本节作为附录,汇总常见输出分布及其负对数似然形式。选择合适的输出分布,本质上就是选择模型对标签噪声、取值范围和数据形态的假设
连续随机变量分布
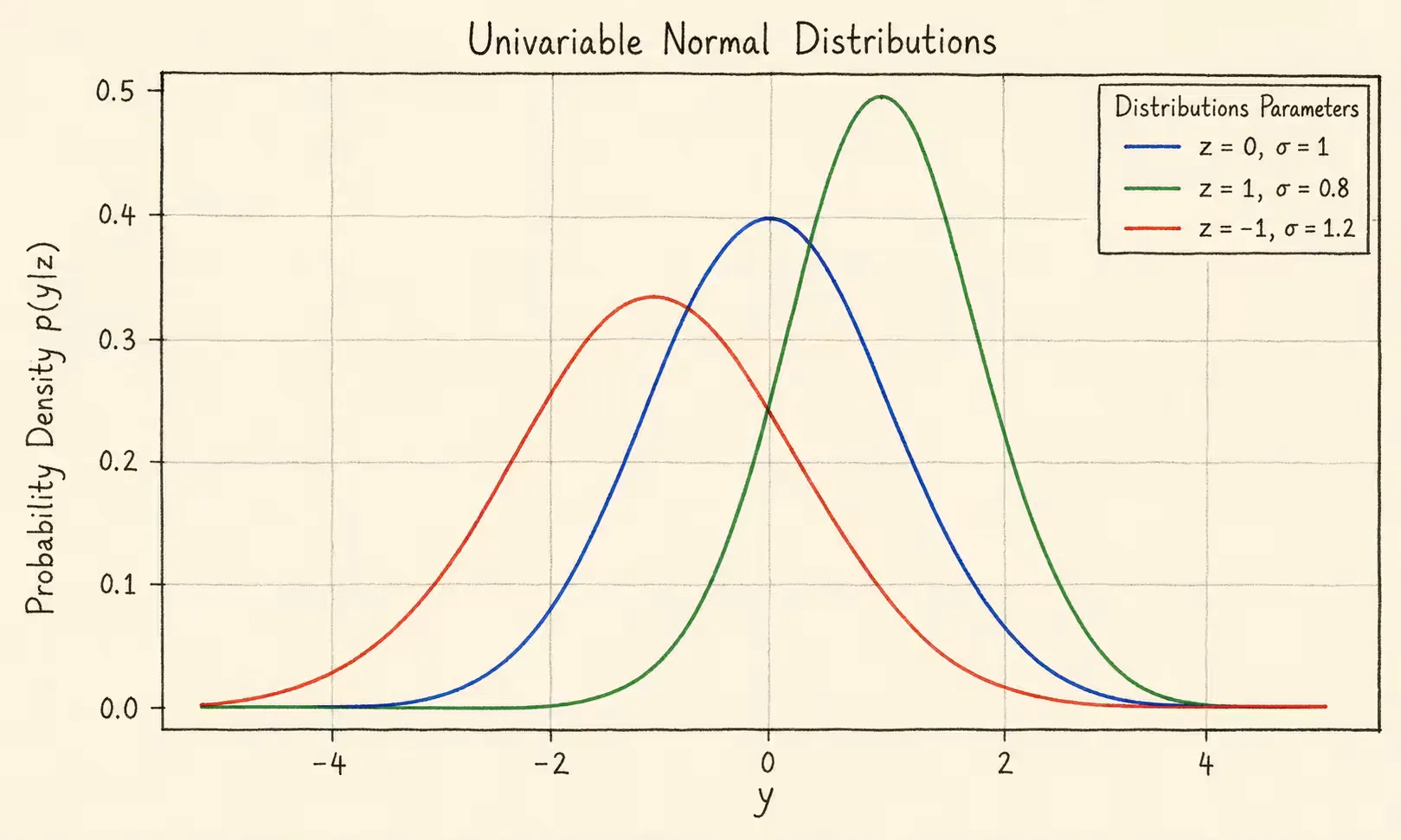
正态分布(单变量)
y∼N(z,σ2)
p(y∣z)=2πσ21exp[−2σ2(y−z)2]
单变量正态分布的概率密度函数曲线如下:
对条件概率取负对数后,可得到平方误差损失:
argmin−logp(y∣z)=argmin[21log[2πσ2]+2σ2(y−z)2]=argmin[(y−z)2](σisconstant)
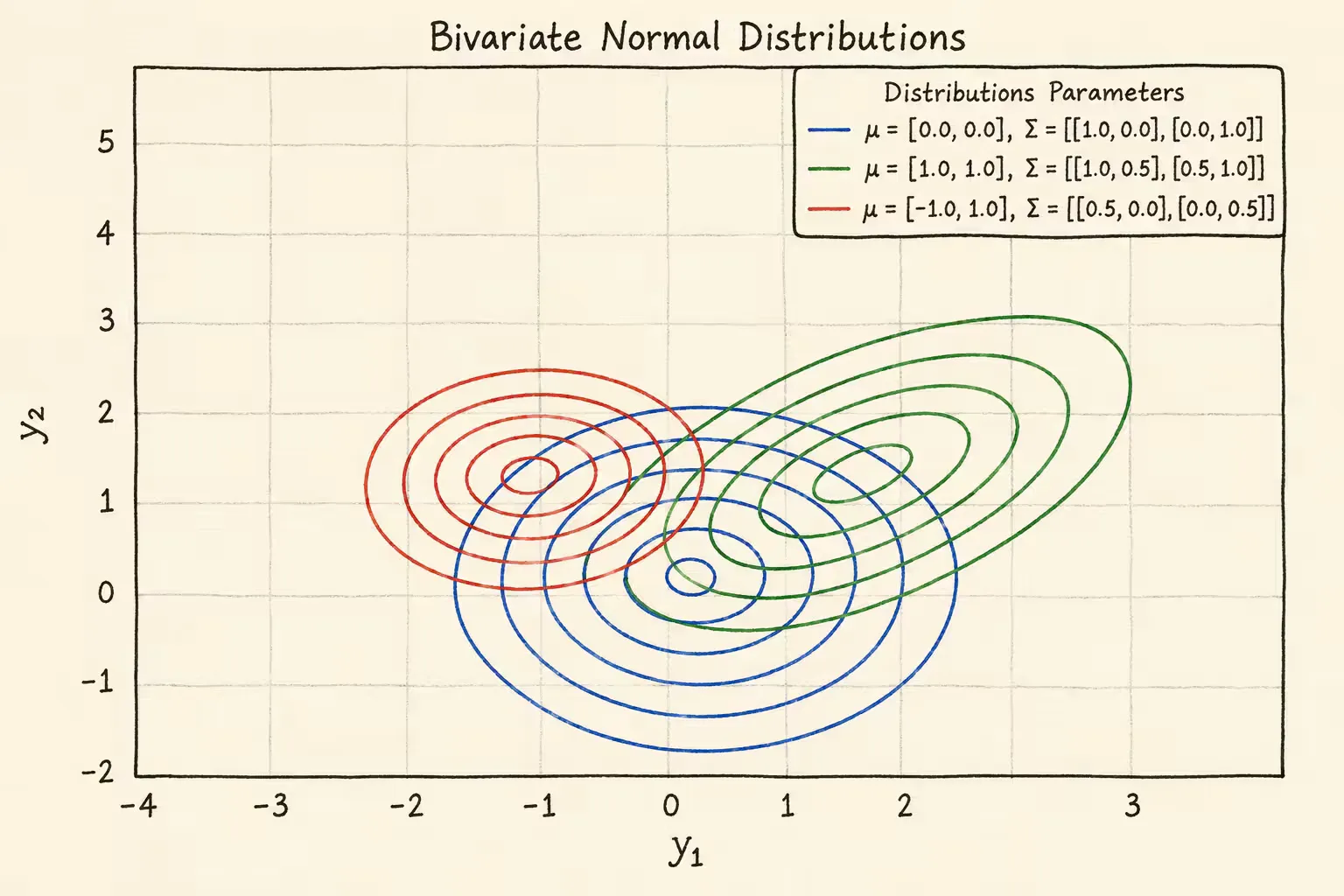
正态分布(多变量)
y∼N(z,Σ)
p(y∣z)=(2π)K/2∣Σ∣1/21exp[−2(y−z)TΣ−1(y−z)]
二维正态分布的概率密度等高线如下
同理,对条件概率取负对数,可得到多变量平方误差形式
argmin−logp(y∣z)=argmin[2Klog[2π]+21log∣Σ∣+21(y−z)TΣ−1(y−z)]=argmin[2Klog[2πσ2]+2σ21∣∣y−z∣∣2](Σ=σ2I)=argmin[∣∣y−z∣∣2](σisconstant)
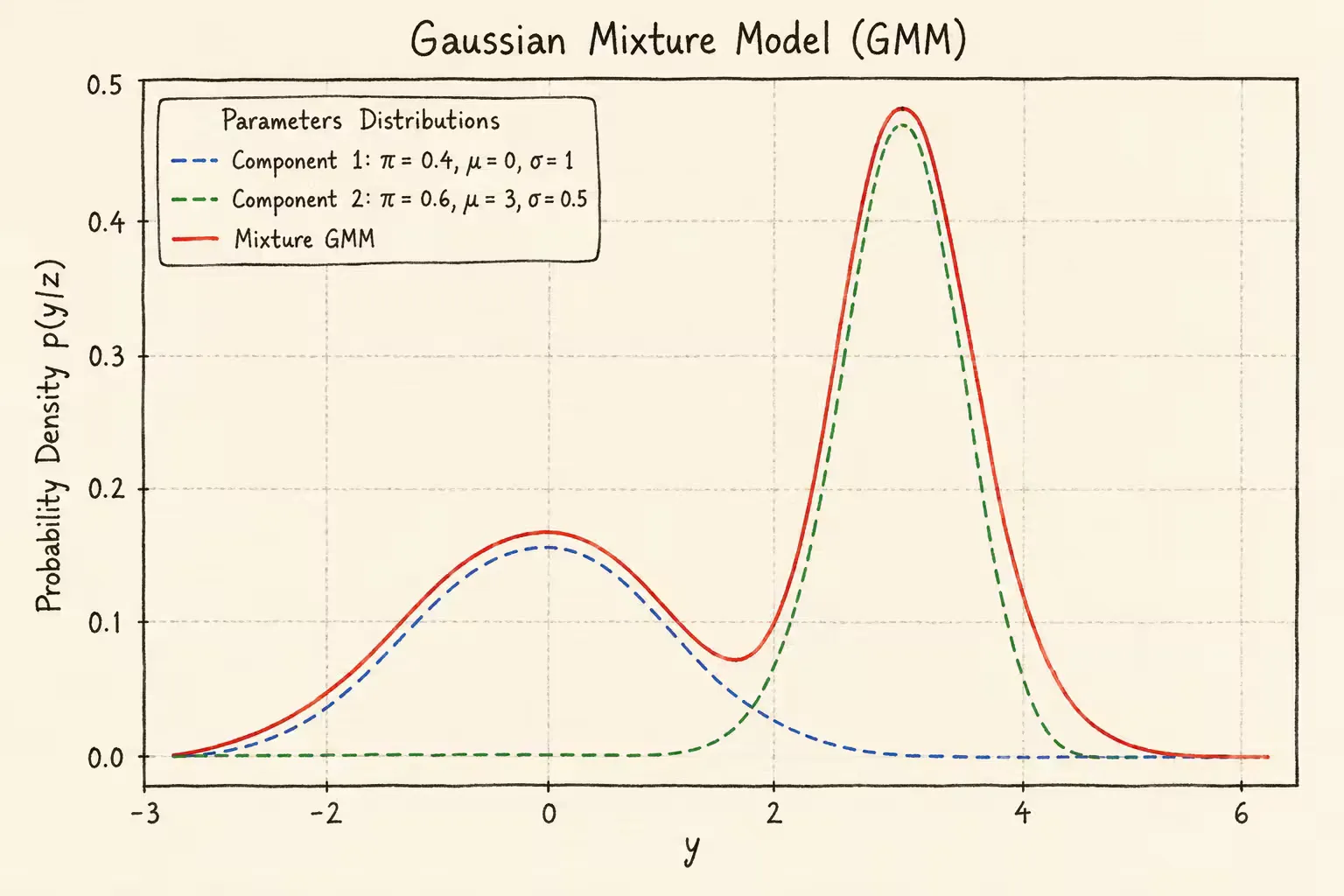
混合高斯分布
y∼GMM(z,σ2)z=[z1,…,zK]T
p(y∣z)=k=1∑KπkN(y∣zk,σk2)
其中πk是第k个高斯分布的权重,满足∑k=1Kπk=1。N(y∣zk,σk2)表示第k个高斯分量的概率密度
混合高斯分布的概率密度如下
对条件概率取负对数,得到混合高斯的损失函数:
argmin−logp(y∣z)=argmin−log[k=1∑Kπk2πσk21exp[−2σk2(y−zk)2]]log-sum-expconstruct=argmin−logk=1∑Kexp[ak](ak=logπk−21log[2πσk2]−2σk2(y−zk)2)=argmin−m−logk=1∑Kexp[ak−m](m=kmaxak)
Laplace分布
y∼Laplace(z,b)
p(y∣z)=2b1exp[−b∣y−z∣]
Laplace分布概率密度如下。μ是位置参数,用于控制分布中心;b是尺度参数,用于控制分布宽度
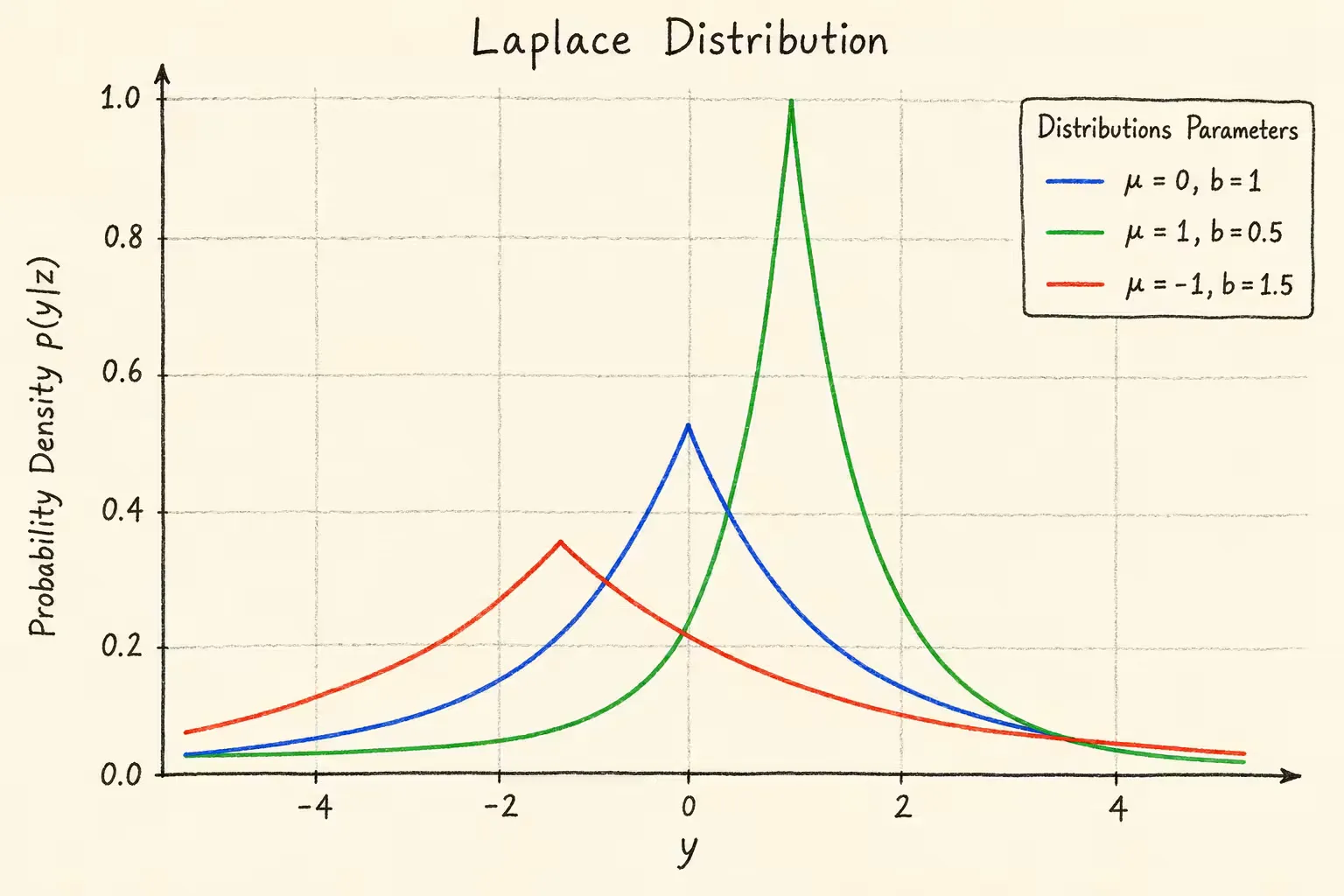
对条件概率取负对数,可得到与绝对误差相关的损失:
argmin−logp(y∣z)=argminlog(2b)+b∣y−z∣
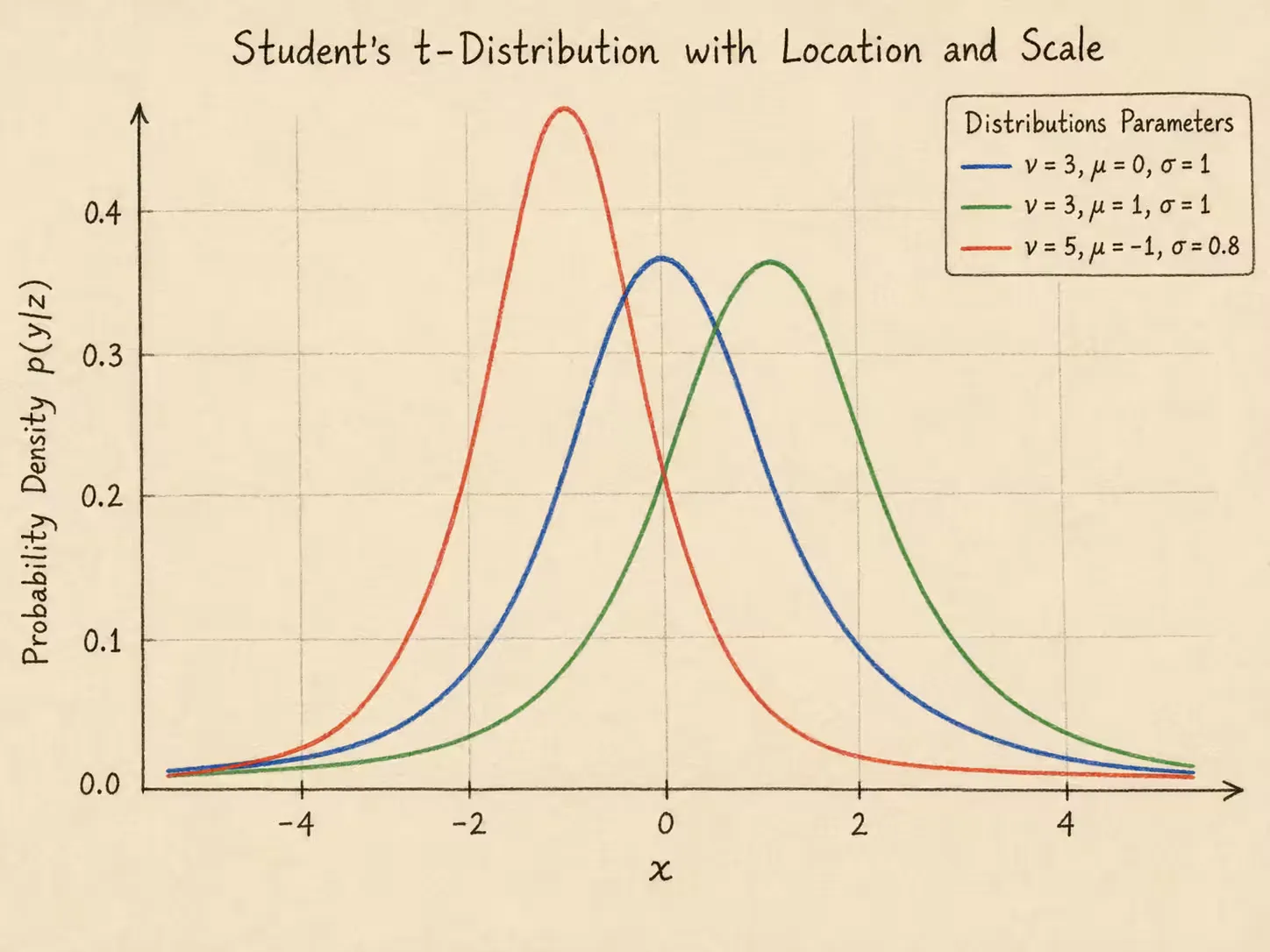
t 分布
y∼t(ν,z)z=[z1,z2]T
p(y∣z)=νπσΓ(2ν)Γ(2ν+1)[1+ν1(exp[z2]y−z1)2]−2ν+1
t分布的概率密度如下。其中μ表示位置参数,σ>0表示尺度参数,ν>0表示自由度
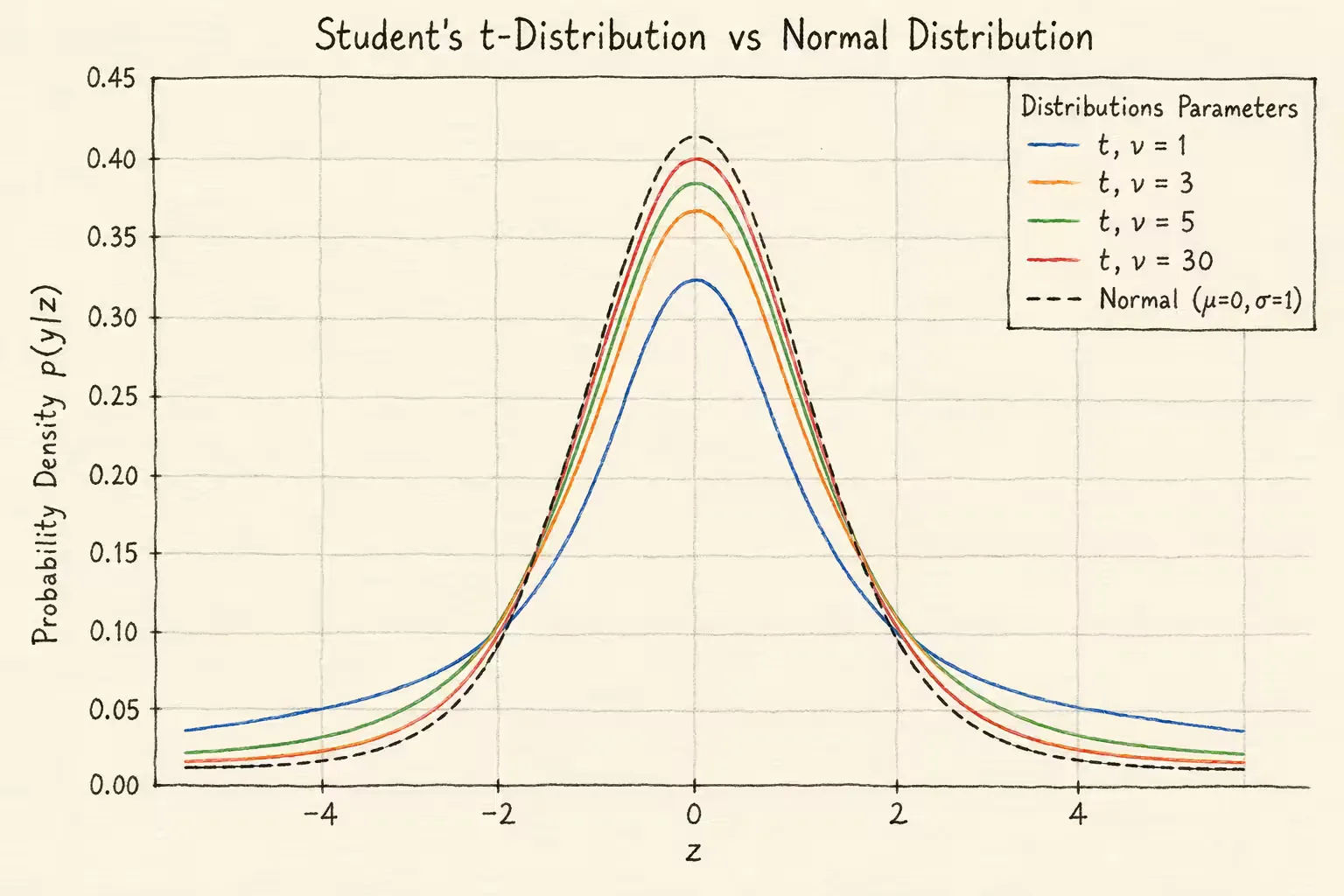
t分布和单变量正态分布在不同自由度下的概率密度对比如下
对条件分布取负对数,可得到对应损失:
argmin−logp(y∣z)=argminz2+2ν+1log(1+ν1exp[2z2](y−z1)2)+C(C=−logΓ(2ν+1)+logΓ(2ν)+21log(νπ))=argminz2+2ν+1log(1+ν1exp[2z2](y−z1)2)
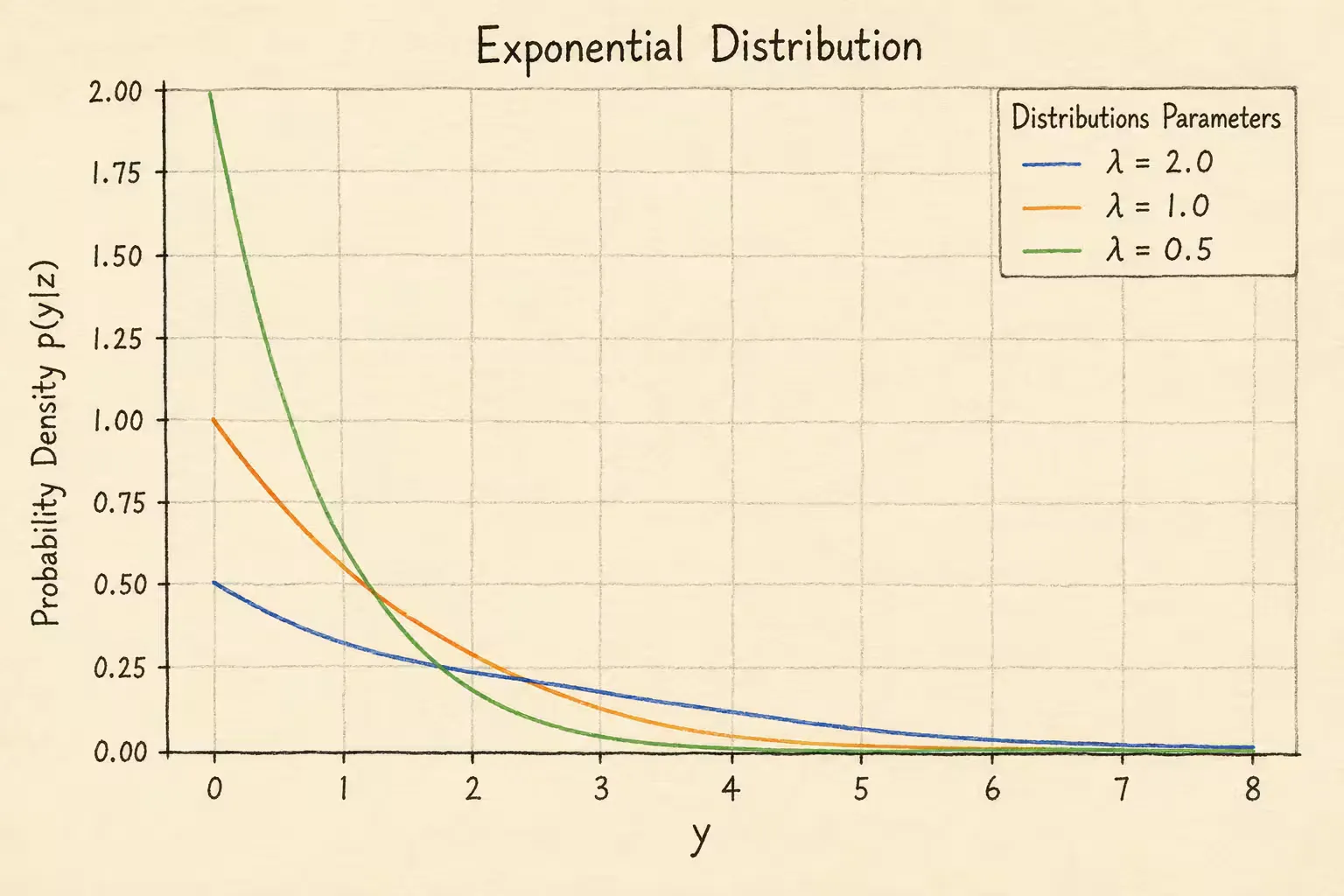
指数分布
y∼Exponential(exp[z]1)
p(y∣z)={exp[z]1exp[−exp[z]y],0,y≥0y<0
指数分布的概率密度如下
对条件分布取负对数,可得到对应损失:
argmin−logp(y∣z)=argminz+yexp[−z](y≥0)
gamma 分布
y∼Gamma(z)z=[z1,z2]T
p(y∣z)={Γ(exp(z1))exp[z2]exp[z1]1yexp[z1]−1exp[−exp[z2]y]0,y≥0y<0
gamma分布的概率密度如下。其中k>0表示形状参数,θ>0表示尺度参数
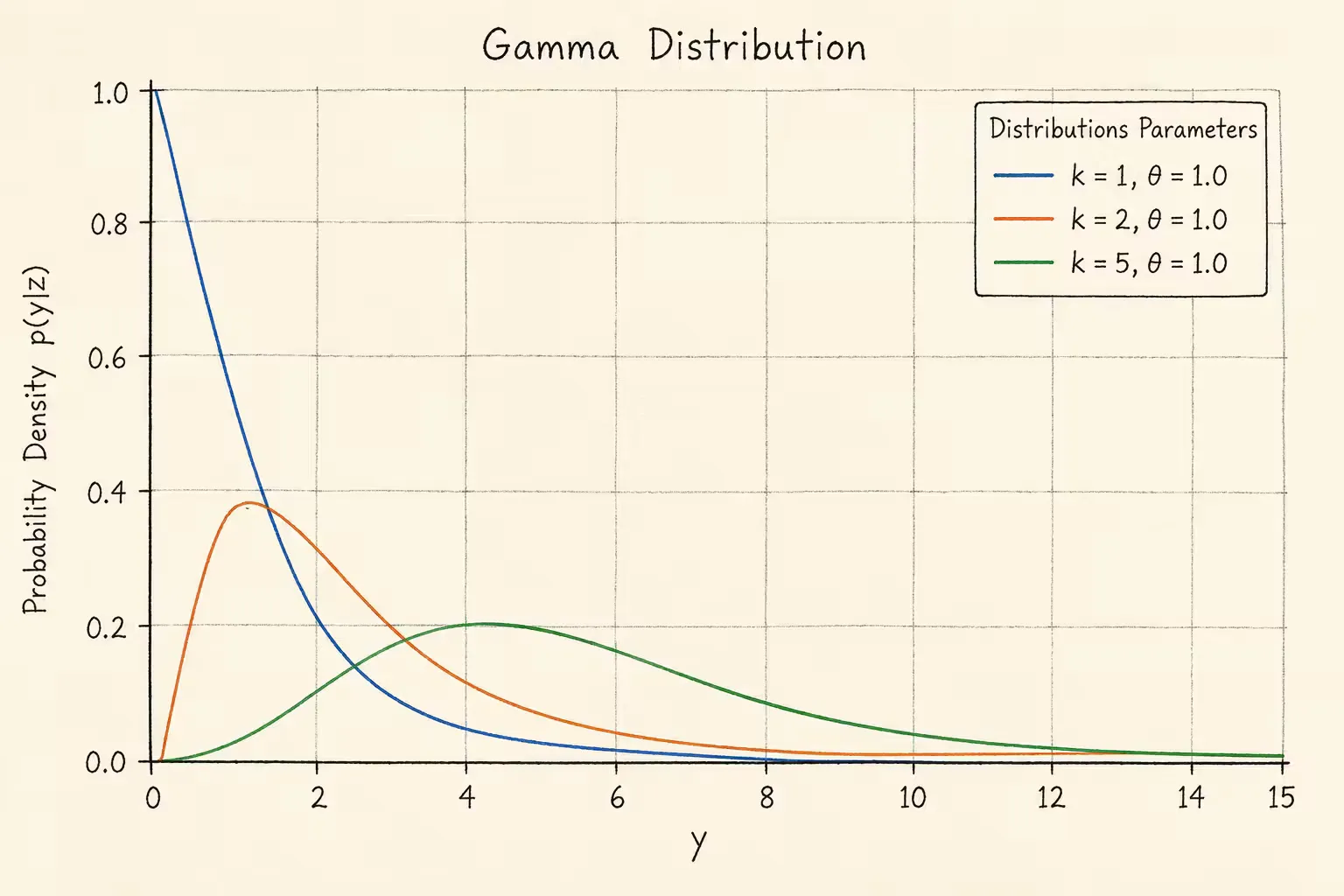
对条件分布取负对数,可得到对应损失:
argmin−logp(y∣z)=argminlogΓ(exp[z1])+exp[z1]z2−(exp[z1]−1)logy+yexp[−z2](y≥0)
beta 分布
y∼Beta(z)z=[z1,z2]T
p(y∣z)=B(exp[z1],exp[z2])1yexp[z1]−1(1−y)exp[z2]−1
beta分布的概率密度函数如下。其中α>0,β>0均为形状参数
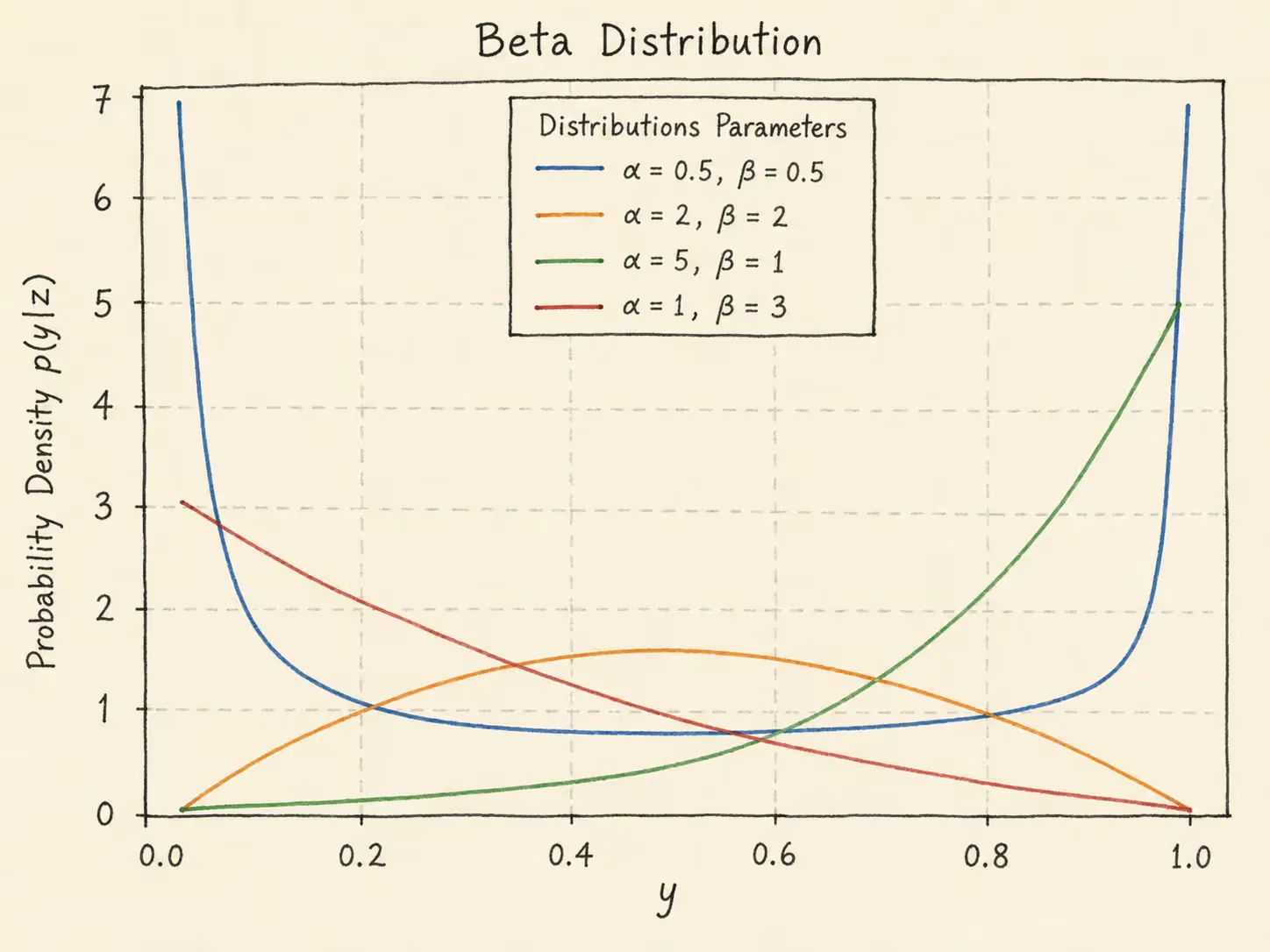
先记:
logB(exp[z1],exp[z2])=logΓ(exp[z1])+logΓ(exp[z2])−logΓ(exp[z1]+exp[z2])
对条件分布取负对数,可得到对应损失:
argmin−logp(y∣z)=argminlogB(exp[z1],exp[z2])−(exp[z1]−1)logy−(exp[z2]−1)log(1−y)(y∈[0,1])
离散随机变量分布
Poisson分布
y∼Poisson(exp[z])
p(y∣z)=y!exp[z]yexp[−exp[z]]
对条件分布取负对数,可得到对应损失:
argmin−logp(y∣z)=argminexp[z]−yz+C(C=log[y!])=argminexp[z]−yz
Bernoulli分布
y∼Bernoulli(sigmoid(z))
p(y∣z)=sigmoid(z)y(1−sigmoid(z))1−y
分类分布
p(y∣z)=softmaxy(z)=∑y′=1Kexp[zy′]exp[zy]
不同概率之间的距离
Kullback−Leibler散度(KL散度)
KL散度用于衡量两个概率分布的差异。需要注意,KL 散度不是严格意义上的距离,因为它通常不对称
DKL[p(y)∣∣q(y)]=∫−∞∞p(y)log[p(y)]dy−∫−∞∞p(y)log[q(y)]dy
两个多维正态分布之间的KL散度为:
DKL[N(μ1,Σ1)∣∣N(μ2,Σ2)]=21(log[∣Σ1∣∣Σ2∣]−D+tr[Σ2−1Σ1]+(μ2−μ1)TΣ2−1(μ2−μ1))
Jensen−Shannon散度(JS散度)
KL散度通常不对称:
DKL[p(y)∣∣q(y)]=DKL[q(y)∣∣p(y)]
因此,可以基于 KL 散度构造对称化的JS散度。
DJS[p(y)∣∣q(y)]=21DKL[p(y)∣∣2p(y)+q(y)]+21DKL[q(y)∣∣2p(y)+q(y)]
它可以理解为p(y)和q(y)分别到混合分布2p(y)+q(y)的平均散度。
Fréchet/Wasserstein-2 距离
两个概率分布p(x)和q(y)之间的二阶 Wasserstein 距离可写为:
DFr[p(x)∣∣q(y)]=π(x,y)min[∫∫π(x,y)∣x−y∣2dxdy]
其中π(x,y)表示所有边缘分布分别为p(x)和q(y)的联合分布
两个多维正态分布之间常用如下闭式形式,常见于 FID 指标:
DFr/W2[N(μ1,Σ1)∣∣N(μ2,Σ2)]=∣μ1−μ2∣2+tr[Σ1+Σ2−2(Σ2Σ1)1/2]