Article
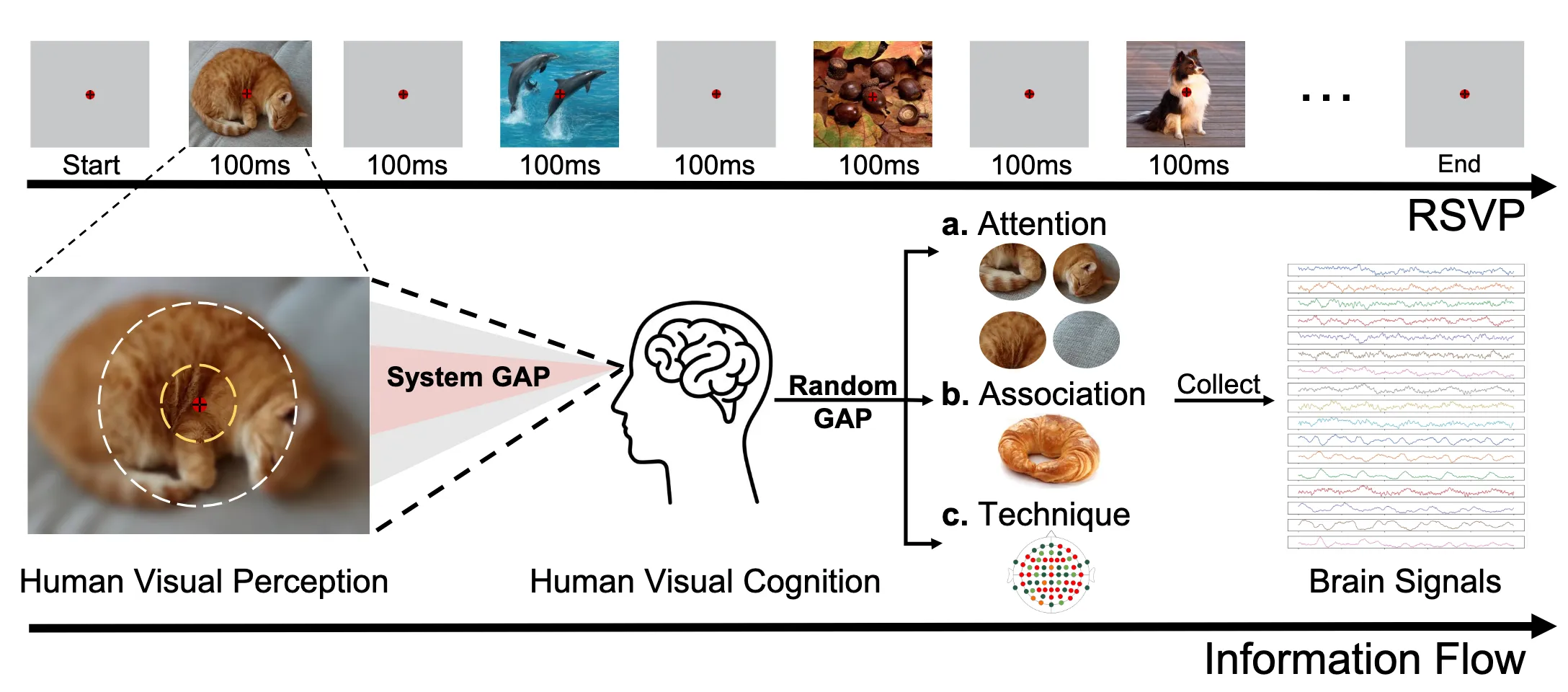
EEG解码图像
核心问题与标准流程
EEG 视觉解码的核心问题是:给定人在观看图像时记录到的 EEG,能否恢复图像类别、检索原图,甚至重建视觉内容?
近两年的主流路线不是直接从 EEG 生成像素,而是先把 EEG 映射到强视觉模型的表征空间,尤其是 CLIP / OpenCLIP 这类图文对齐空间:
EEG signal -> EEG encoder -> visual embedding -> retrieval / reconstruction这个 visual embedding 同时服务两个任务:
- 检索:验证 EEG embedding 是否靠近正确图像
- 重建:作为生成器的条件输入
检索和重建不是两条独立路线,而是同一个 EEG-to-visual embedding pipeline 的两个出口。检索指标验证对齐质量,重建结果展示这个 embedding 经过生成器后能否形成合理视觉内容
当前研究的核心分歧在于:应该改进 EEG encoder,改进 visual target space,还是统一 EEG / MEG / fMRI 到一个神经表征空间?
研究脉络:三条并行路线
当前 EEG 视觉解码研究沿着三条并行路线发展,每条路线针对不同的瓶颈:
路线一:增强 EEG encoder
从 NICE-EEG 的轻量 TSConv 到 ATM 的 channel-wise attention + subject tokens,这条路线认为瓶颈在脑电编码器表达能力不足
路线二:改进 visual target space
从 UBP 的 blur prior 到 ViEEG 的层级目标,再到 Perceptogram 的线性 baseline,这条路线认为瓶颈在视觉目标与脑信号的兼容性
路线三:统一神经表征空间
BrainFLORA 将 EEG / MEG / fMRI 统一到一个共享空间,这条路线认为瓶颈在跨模态泛化能力
这三条路线不是互斥的,而是从不同角度改进同一个 pipeline。理解它们的设计动机和实验证据,是判断下一步方向的关键
路线一:增强 EEG Encoder
NICE-EEG:最小 baseline
Song et al. 的 Decoding Natural Images from EEG for Object Recognition 建立了这条路线的起点
NICE-EEG 用 TSConv(temporal-spatial convolution)作为轻量 EEG 编码器,将 EEG 表征与冻结 CLIP 图像特征做对比学习,解决 200-way zero-shot object classification
它的价值在于系统极简:EEG encoder、图像特征、对比损失和模板匹配评估构成了一个可复现的最小系统。它不急于做图像生成,而是先证明 EEG 和视觉表征之间可以建立可用对齐
NICE-EEG 报告 THINGS-EEG subject-dependent 200-way top-1 accuracy 13.8%,top-5 39.5%。这个数字成为后续方法的重要 baseline
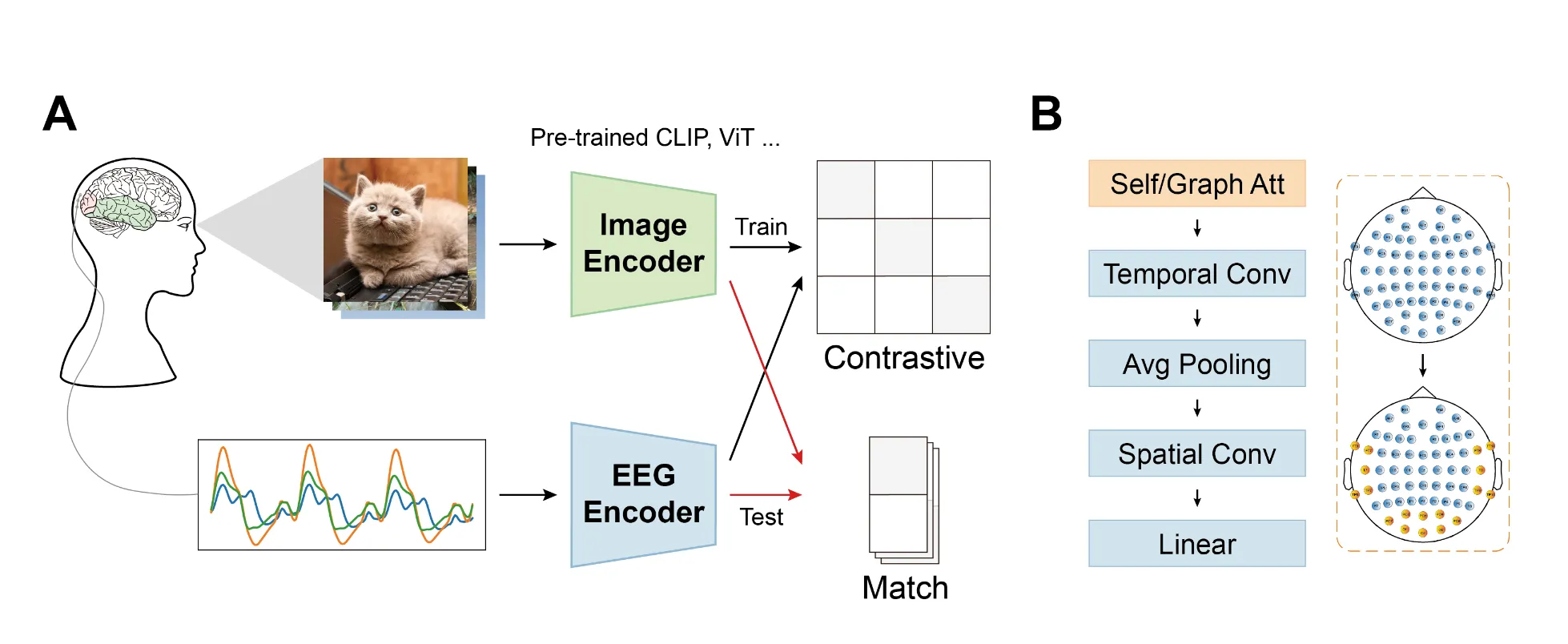
ATM:从检索到重建的完整 pipeline
Li et al. 的 Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion 在 NICE-EEG 基础上做了两个扩展:
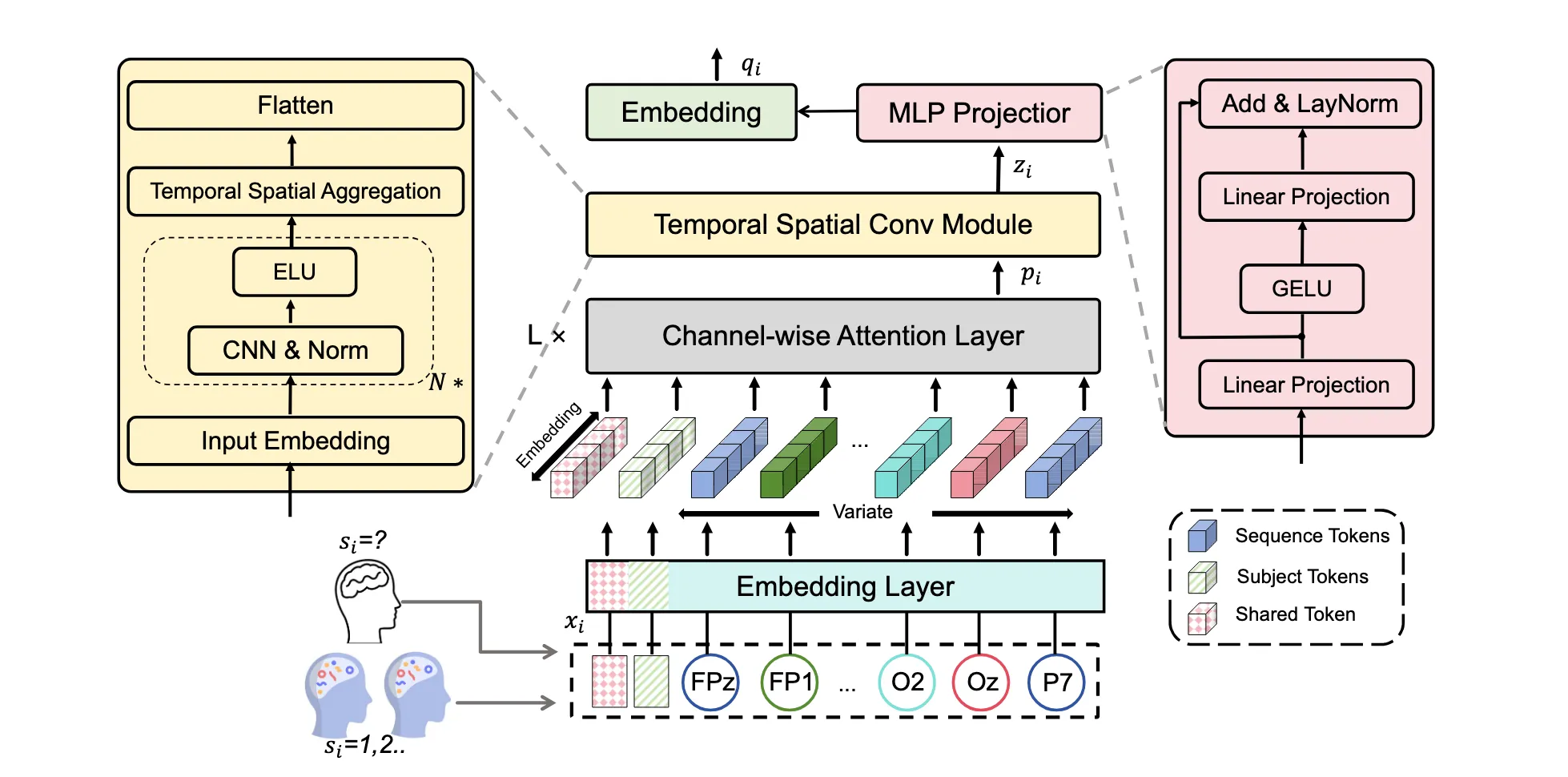
- 更强的 EEG encoder:Adaptive Thinking Mapper (ATM) 在 TSConv 前加入 channel-wise attention 和 subject tokens
- 完整的重建路径:通过 prior diffusion 将 EEG embedding 转换为图像
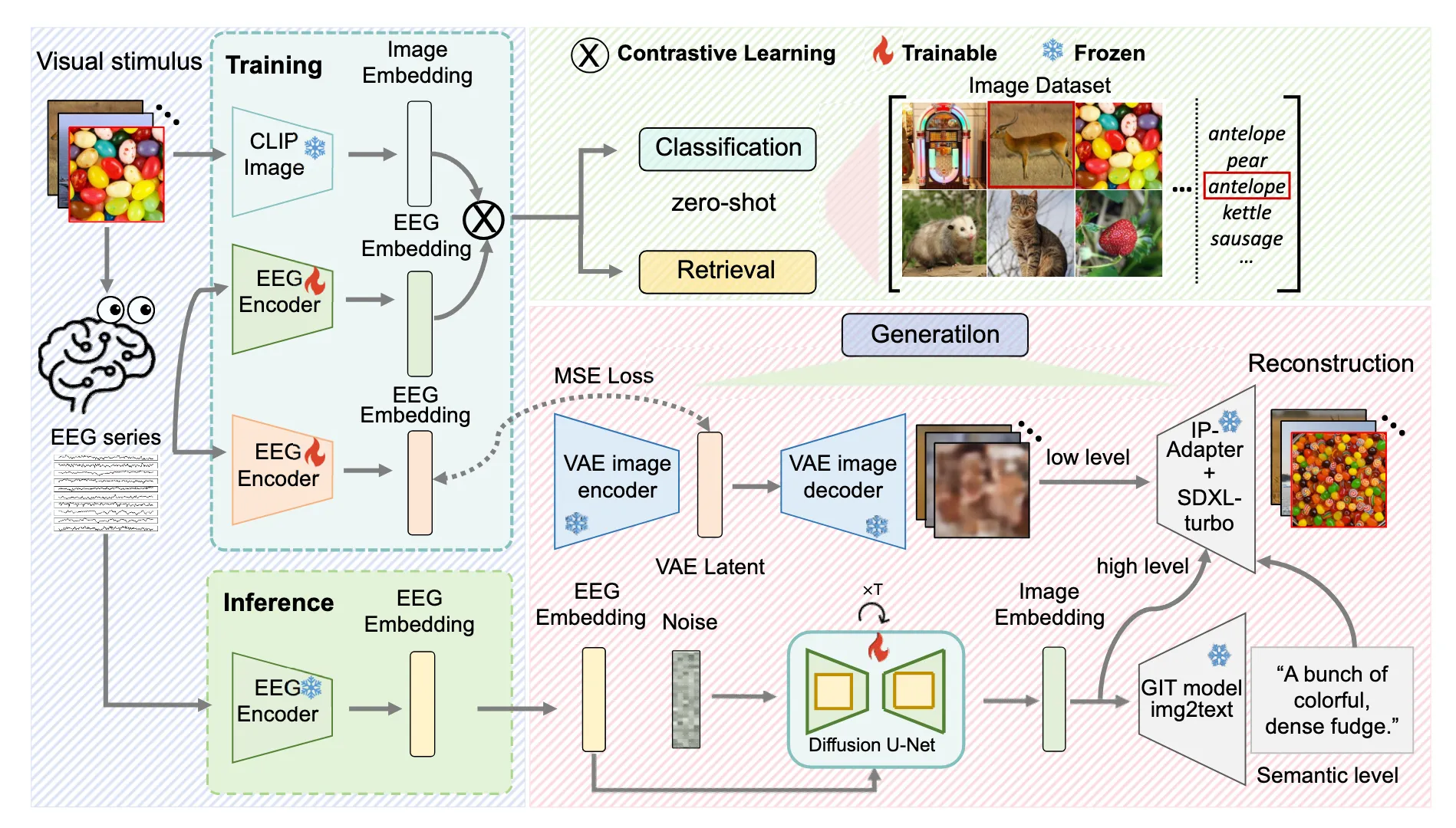
ATM 的关键设计是让分类、检索和重建共享同一个 EEG embedding:
EEG -> ATM encoder -> EEG embedding
├─> retrieval / classification (验证对齐质量)
└─> prior diffusion -> generator -> reconstructed image (展示生成能力)这个设计很重要:生成图像质量不能单独说明 EEG 解码能力,因为 diffusion generator 本身有很强的图像先验。必须同时报告检索指标来验证 EEG embedding 确实靠近正确图像
ATM 报告 THINGS-EEG subject-dependent 200-way retrieval top-1 28.64%,top-5 58.47%,显著超过 NICE-EEG baseline
路线二:改进 Visual Target Space
路线一假设瓶颈在 EEG encoder,路线二则认为问题在于 CLIP 图像空间可能不适合脑信号对齐
这条路线的核心观察是:CLIP 是在自然图像上训练的,它的表征包含很多高频细节、纹理信息和像素级特征。但 EEG 信号噪声大、空间分辨率低,可能无法稳定预测这些细节
因此,路线二的方法不是增强 EEG encoder 去拟合 CLIP,而是改造 visual target 让它更接近 EEG 的信息容量
CognitionCapturer:多模态目标扩展
Zhang et al. 的 CognitionCapturer 认为 image-only alignment 可能低估了 EEG 中的语义和结构信息
它的思路是:既然 EEG 不只对应图像外观,也可能包含语言语义、空间结构等多层信息,那就用多个监督目标来捕获这些信息
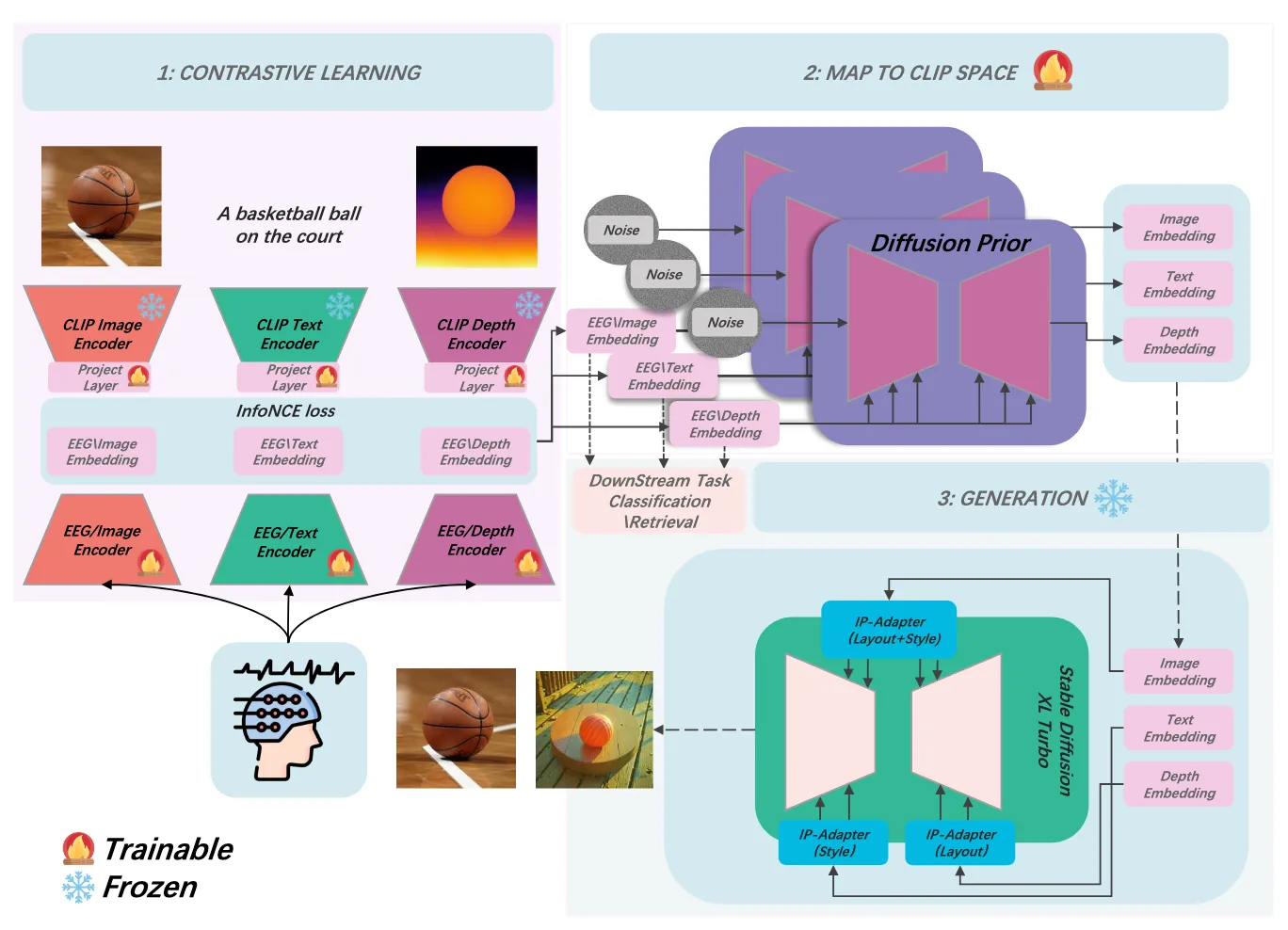
CognitionCapturer 把每张图像扩展成三个监督目标:
- 图像特征:CLIP 图像 embedding
- 文本描述:BLIP-2 生成的 caption
- 深度图:Depth Anything 生成的深度信息
然后训练三个 EEG expert encoder,分别对齐这三种目标
这个方向的问题也很明确:caption 和 depth 都是外部模型生成的辅助标签,可能引入模型偏差。论文中的 “all” 指标更像互补性上界,不是实际部署准确率
ViEEG:层级视觉目标
Liu et al. 的 ViEEG 继续推进多目标思想,但采用了不同的分解策略
它不是并列加入 caption 和 depth,而是把视觉目标按视觉加工层级拆成三个层次:
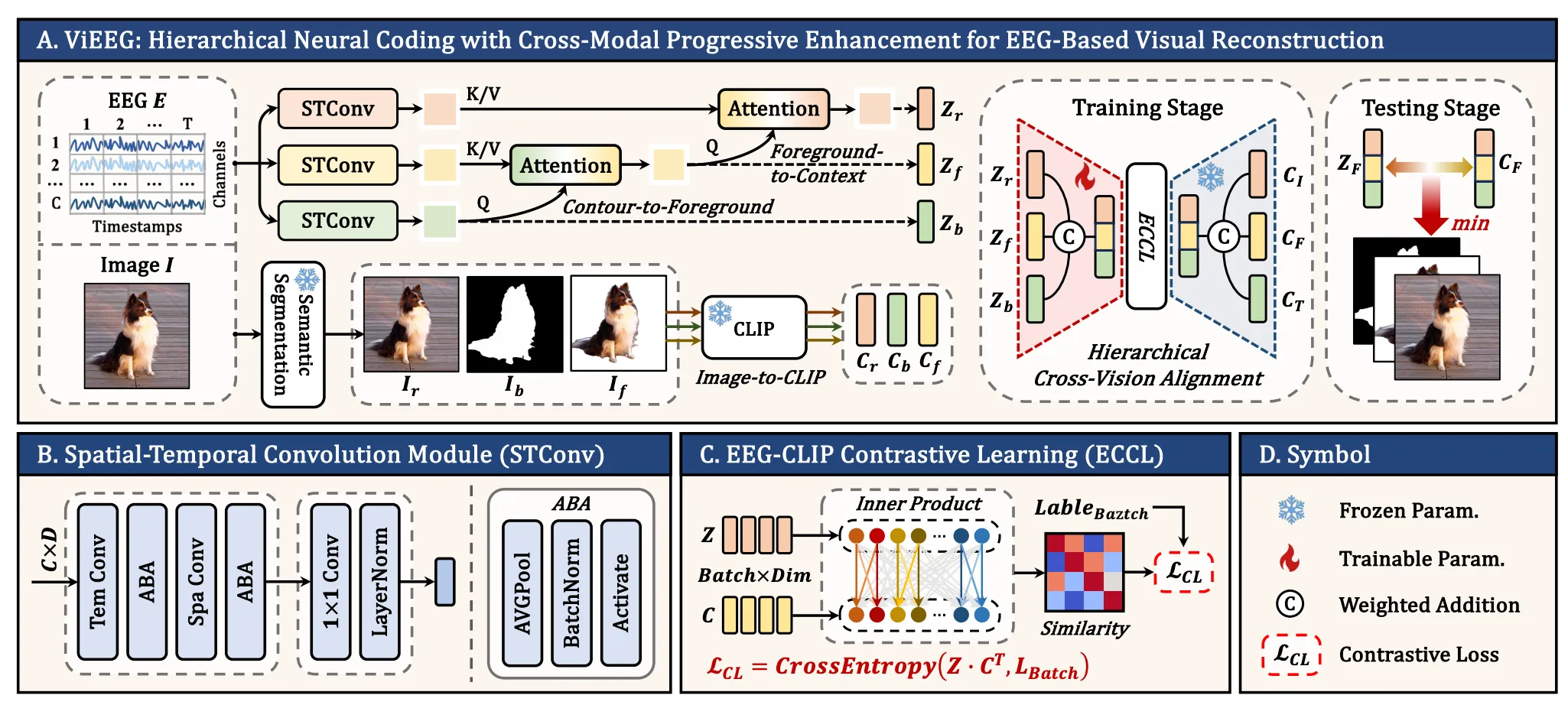
- Contour:二值 mask,对应低级边界信息
- Object:前景物体,对应中级物体表征
- Context:完整场景,对应高级场景理解
三种图像视图分别进入冻结 CLIP,形成三组视觉 target。EEG 侧也对应三条 STConv stream,通过 bottom-up cross-attention 融合
mask view -> contour CLIP target
foreground view -> object CLIP target
raw image -> context CLIP target
EEG streams -> bottom-up fusion -> hierarchical EEG embeddingViEEG 报告 THINGS-EEG subject-dependent 200-way top-1 40.9%,top-5 74.5%,显著超过 ATM 和 NICE-EEG
但它也带来新的 caveat:mask 和 foreground 来自外部分割模型,重建又依赖 SDXL / IP-Adapter。提升需要和 segmentation quality、CLIP target geometry、diffusion prior 分开看
UBP:目标简化而非扩展
Wu et al. 的 Bridging the Vision-Brain Gap with an Uncertainty-Aware Blur Prior 提出了与 CognitionCapturer 和 ViEEG 相反的观点
CognitionCapturer 和 ViEEG 都在扩展视觉目标(加入 caption/depth,或拆分成 contour/object/context),而 UBP 选择简化视觉目标
UBP 的核心观察是:CLIP 图像特征可能太细,包含很多 EEG 不稳定或根本无法表达的高频视觉细节。如果直接对齐完整图像 embedding,模型会被迫拟合不可靠信息
UBP 的做法是在图像进入 CLIP 前先做 blur,尤其是 foveated blur(模拟人眼中心凹视觉)。它根据脑-图像配对的不确定性动态调整模糊程度
UBP 报告 THINGS-EEG intra-subject 200-way retrieval top-1 50.9%,top-5 79.7%,是当前最高的检索结果
这个思路同样服务检索和重建:更合适的 target 可以提高 EEG-image 对齐,也能给生成器提供更稳定的条件
Perceptogram:线性 baseline 的挑战
Fei et al. 的 Perceptogram 提出了一个更激进的观点:如果目标 latent space 足够结构化,复杂 EEG encoder 可能不是必要条件
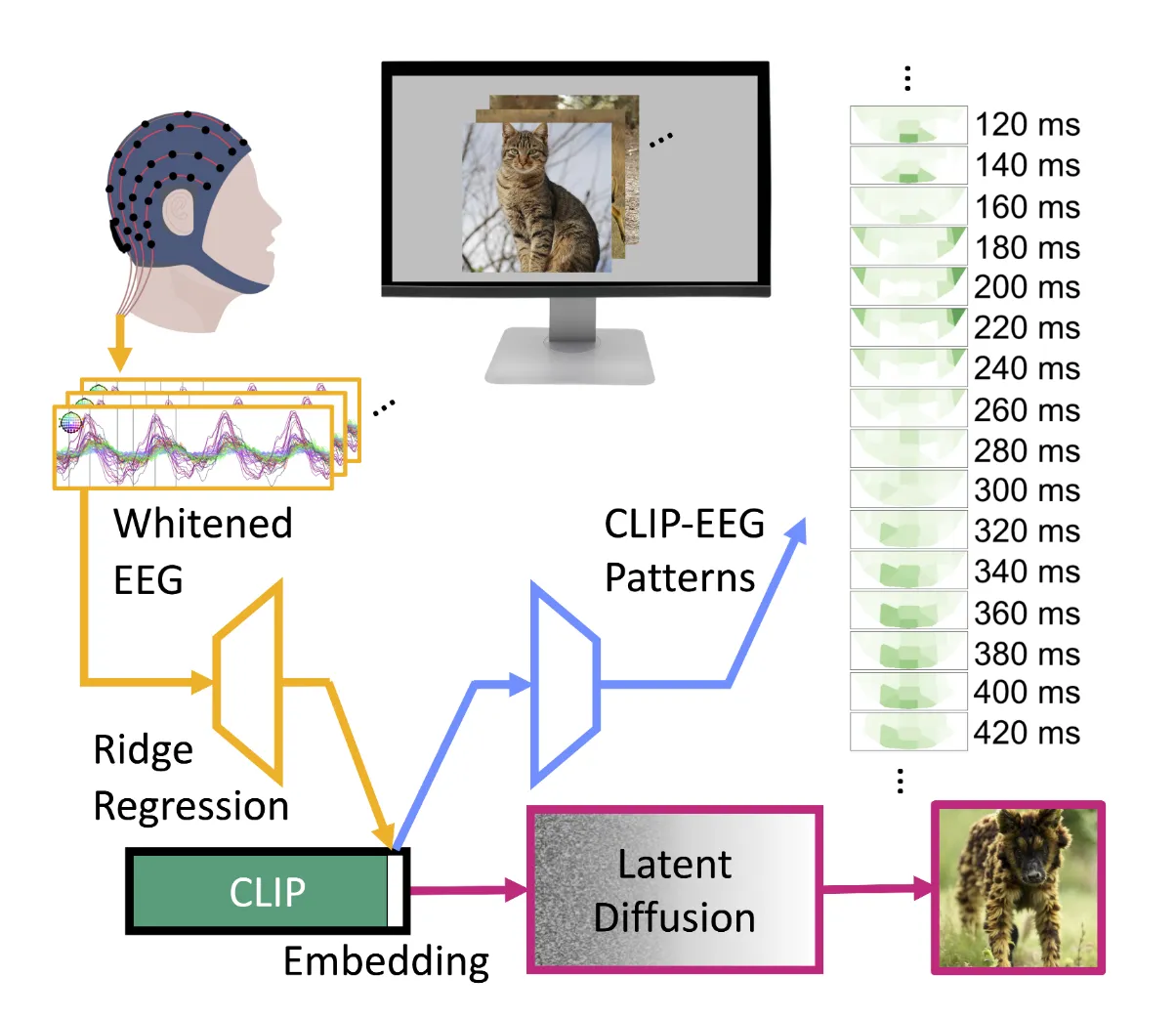
Perceptogram 使用平均后的 EEG,通过线性回归映射到 CLIP / unCLIP / VAE / VDVAE 等视觉 latent,再用冻结 reconstructor 重建图像
averaged EEG -> linear regression -> visual latent
visual latent -> retrieval / frozen reconstructor -> imagePerceptogram 报告 THINGS-EEG2 linear EEG-to-CLIP retrieval Recall@1 25.0%,Recall@5 50.0%,重建指标与深度模型相当
这个工作的重要性在于:它提醒我们,如果深模型超过 baseline,需要说明收益来自 EEG encoder、目标 latent、重复平均,还是生成器先验
Perceptogram 还用 EEG -> latent -> EEG 的 decode-encode loop 分析语义、纹理、颜色、亮度对应的电极和时间窗,提供了可解释性工具
路线三:统一神经表征空间
BrainFLORA:跨模态统一建模
Li et al. 的 BrainFLORA 把问题从 EEG-only 推到 EEG / MEG / fMRI 统一建模
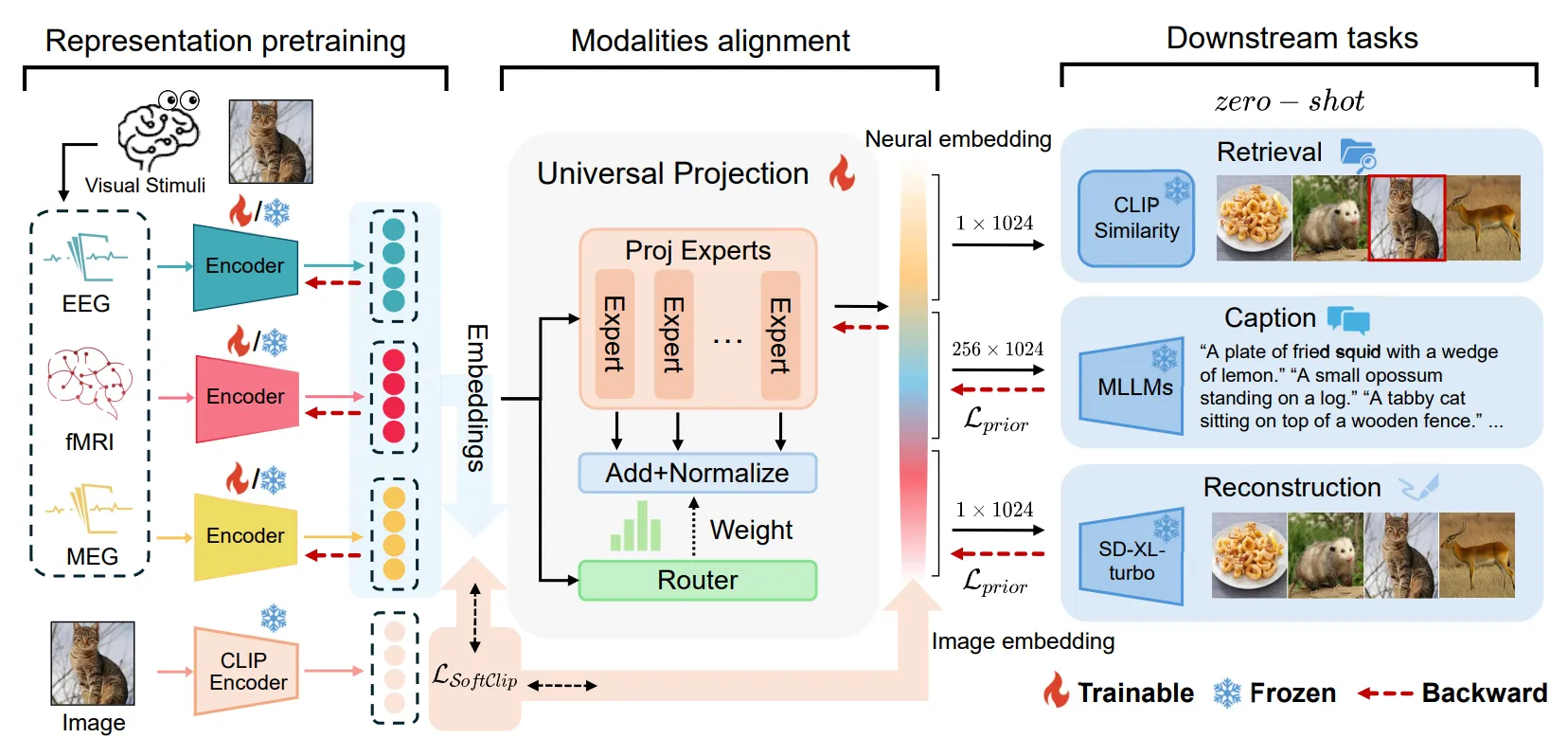
它不只问 EEG 能否对齐 CLIP,而是问不同神经记录模态能否通过一个共享 projector 落到同一个视觉语义空间里
BrainFLORA 为 EEG、MEG、fMRI 使用各自的 neural encoder,再通过 soft-router MoE universal projector 对齐到 CLIP ViT-L/14 embedding
EEG / MEG / fMRI -> modality encoder
modality encoder -> soft-router MoE projector
projected neural embedding <-> CLIP image embedding
projected neural embedding -> retrieval / reconstruction / captioning / concept analysisBrainFLORA 报告 THINGS-EEG2 joint-subject 200-way retrieval top-1 25.05%,top-5 56.35%,THINGS-MEG top-1 6.88%,top-5 23.38%
它的重要性不在于单个 EEG benchmark 必然压过所有专门模型,而在于把 visual neural decoding 改写成统一表征学习问题
同一个 embedding 可以用于检索、重建、captioning 和 concept-space analysis。这让 evaluation 不再只看图像是否像,还能看神经表征是否保留 object concept 的相似结构
设计张力:扩展 vs 简化,深度 vs 线性
从上述研究脉络来看,当前存在几个核心设计张力:
张力一:目标扩展 vs 目标简化
- CognitionCapturer 和 ViEEG 扩展视觉目标(加入 caption/depth,或拆分成 contour/object/context)
- UBP 简化视觉目标(blur 掉高频细节)
- 两者都在解决 target mismatch,但方向相反
张力二:深度编码器 vs 线性 baseline
- ATM 增强 EEG encoder(channel-wise attention + subject tokens)
- Perceptogram 证明线性回归已经很强
- 这提醒我们:不能轻易把收益归因于深模型
张力三:任务专用 vs 跨模态统一
- NICE-EEG、ATM、UBP、ViEEG 都是 EEG-only 专用模型
- BrainFLORA 统一 EEG / MEG / fMRI
- 统一模型可能在某些任务上不如专用模型,但泛化能力更强
张力四:检索 vs 重建
- 检索验证 EEG embedding 是否靠近正确图像(更直接的对齐指标)
- 重建展示生成能力(但可能主要来自生成器先验)
- 同时报告两者,不能只看重建样例
旁支方法:反向对齐与知识蒸馏
CLIP 知识蒸馏路线
Ferrante et al. 的 Decoding EEG signals of visual brain representations with a CLIP based knowledge distillation 采用了不同的路线
它不直接回归 CLIP embedding,而是用 CLIP 图像分类器作为 teacher,训练 EEG 时频 CNN student
这个流程更像 classification bottleneck:先从 EEG 预测类别,再用类别 prompt 生成语义图像
这类方法适合类别级语义重建,但不是精确图像检索或低层视觉恢复
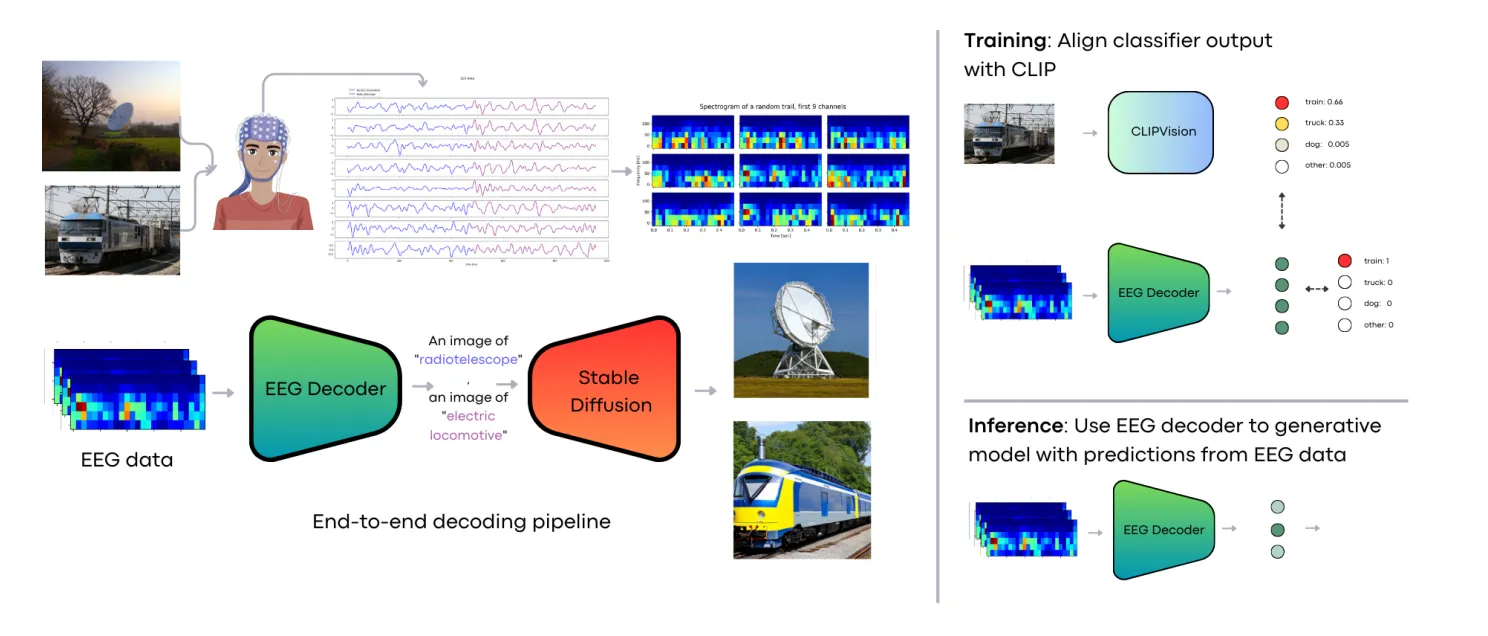
反向对齐:用 EEG 改进视觉模型
Lu et al. 的 Achieving more human brain-like vision via human EEG representational alignment 则反过来使用 EEG
它不是从 EEG 解码图像,而是让视觉模型预测 EEG,使视觉模型内部表征更像人脑
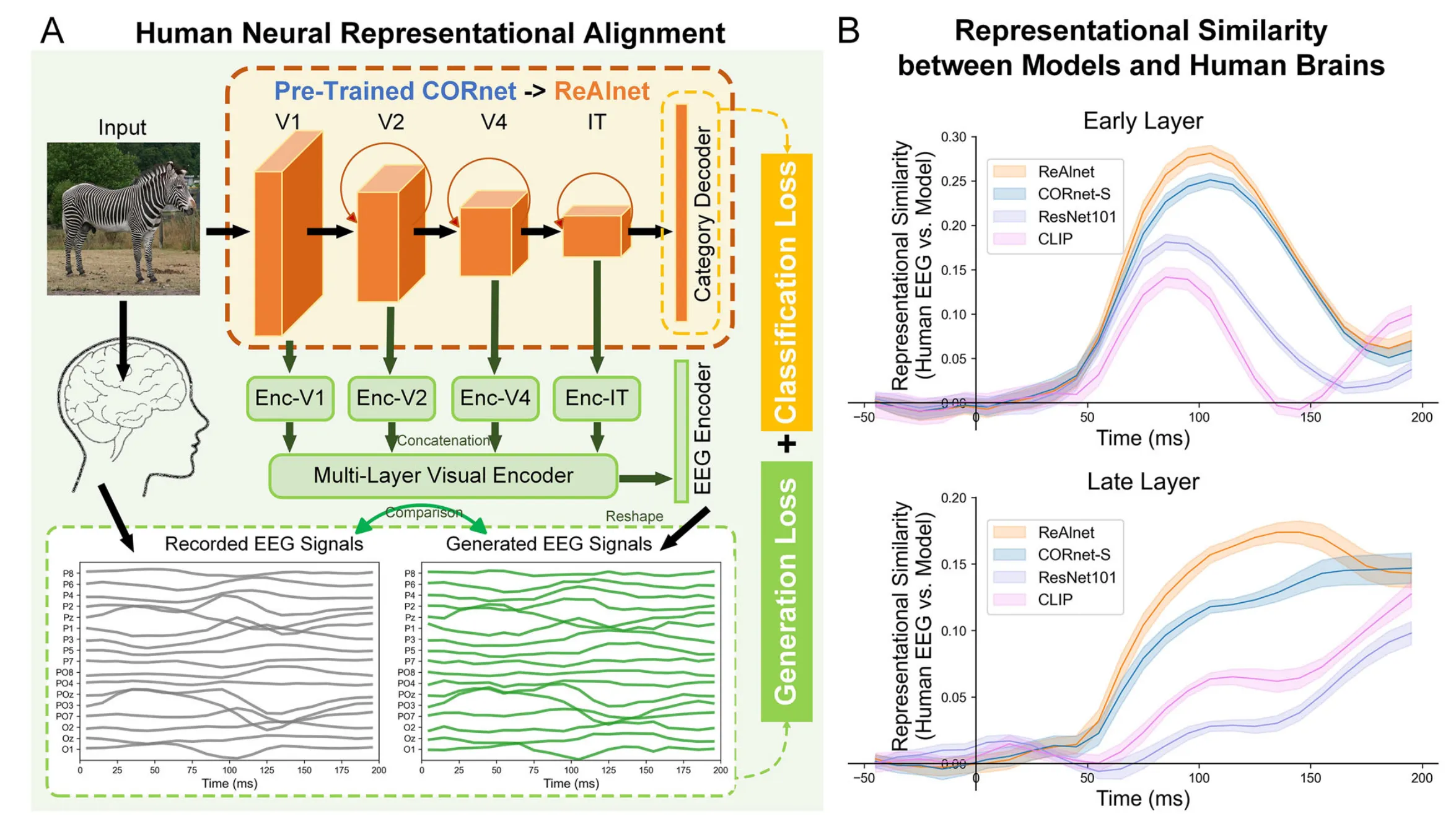
这个方向的重要性在于:未来可以把 EEG-aligned vision model 作为更 brain-compatible 的视觉 target space,再反过来训练 EEG decoder
这形成了一个潜在的闭环:
- 用 EEG 监督训练 brain-aligned vision model(Lu et al.)
- 用 brain-aligned vision model 作为 EEG encoder 的 target space
- 验证这个 target space 是否比原始 CLIP 更适合 EEG 对齐
未来方向:脑兼容目标空间学习
从上述研究脉络来看,下一步的核心问题不应该只是”换哪个 EEG encoder”,而应该是:
在固定强 encoder 后,能否学习更适合脑信号的视觉目标空间?
这个目标空间最好同时满足:
- EEG 更容易预测
- 生成器能用它重建图像
- 在 EEG / MEG / fMRI 或 concept space 中保持稳定结构
为什么是目标空间而非编码器?
这个方向来自几条证据的汇合:
- NICE-EEG 说明最小 contrastive pipeline 可以成立
- ATM 说明同一个 embedding 可以接 retrieval 和 diffusion reconstruction
- CognitionCapturer 和 ViEEG 说明 target 可以多模态、层级化
- UBP 从反方向说明,target 也可能需要删掉 EEG 难以稳定表达的细节
- Perceptogram 提醒我们,线性 EEG-to-latent baseline 已经很强,不能轻易把收益归因于深模型
- BrainFLORA 说明好的 neural embedding 不应只服务 EEG reconstruction,也应能支撑跨模态统一表征
结合我自己的实验,单独从 EEG encoder 角度看,单纯的残差投影层比继续堆叠更复杂的 attention / convolution 组合更有效
总结
EEG 视觉解码研究已经从早期的分类任务发展到检索和重建的完整 pipeline。当前研究沿着三条并行路线发展:
- 增强 EEG encoder:从 NICE-EEG 的 TSConv 到 ATM 的复杂架构
- 改进 visual target:从 UBP 的简化到 ViEEG 的层级化,再到 Perceptogram 的线性 baseline
- 统一神经表征:BrainFLORA 将 EEG / MEG / fMRI 统一到共享空间
核心设计张力在于:目标扩展 vs 简化、深度编码器 vs 线性 baseline、任务专用 vs 跨模态统一
下一步的重点应该是:在固定强 encoder 后,学习更适合脑信号的视觉目标空间
只有检索和重建同时改善,且控制实验排除了预处理、生成器先验等混淆因素,才能说明方法真正改善了 EEG 视觉表征